Long looooong ago, I wrote a deep
review of the XHTML 2.0 spec that was one of the elements that
led to the resuming of the HTML activity at the W3C and the final
dismissal of XHTML 2.0.
Long ago, I started a similar effort on EPUB that led to Dave
Cramer's EPUB Zero. It's
time (fr-FR) to draw some conclusions.
This document is maintained
on GitHub and accepting contributions.
Daniel Glazman
OCF
- EPUB publications are not "just a zip". They are zips with special
constraints. I question the "
mimetype file in first
uncompressed position" constraint since I think the vast
majority of reading systems don't care (and can't care) because most
of the people creating EPUB at least partially by hand don't
know/care. The three last contraints (zip container fields) on the
ZIP package described in section 4.2 of the spec are usually not
implemented by Reading Systems.
- the
container element of the META-INF/container.xml
file has a version attribute that is always "1.0",
whatever the EPUB version. That forces editors, filters and reading
systems to dive into the default rendition to know the EPUB version
and that's clearly one useless expensive step too much.
- having multiple renditions per publication reminds me of MIME
multipart/alternative.
When Borenstein and Freed added it to the draft of RFC 1341 some 25
years ago, Mail User Agents developers (yours truly counted)
envisioned and experimented far more than alternatives between text/html
and text/plain only. I am under the impression
multiple renditions start from the same good will but fail to meet
the goals for various reasons:
- each additional rendition drastically increases the size of
the publication...
- most authoring systems, filters and converters on the market
don't deal very well with multiple renditions
- EPUB 2 defined the default rendition as the first rendition
with a
application/oebps-package+xml
mimetype while the EPUB 3 family of specs defines it as the
first rendition in the container
- while a MIME-compliant Mail User Agent will let you compose a
message in
text/html and output for you the multipart/alternative
between that text/html and its text/plain
serialization, each Publication rendition must be edited
separately.
- in the case of multiple renditions, each rendition has its own
metadata and it's then legitimate to think the publication needs
its own metadata too. But the
META-INF/metadata.xml
file has always been quoted as "This version of the OCF
specification does not define metadata for use in the
metadata.xml file. Container-level metadata may be defined in
future versions of this specification and in IDPF-defined EPUB
extension specifications." by all EPUB specifications.
The META-INF/metadata.xml should be dropped.
- encryption, rights and signatures are per-publication
resources while they should be per-rendition resources.
- the
full-path attribute on rootfile
elements is the only path in a publication that is relative to the
publication's directory. All other URIs (for instance in href
attributes) are relative to the current document instance. I think full-path
should be deprecated in favor of href here, and
finally superseded by href for the next major version
of EPUB.
- we don't need the
mimetype attribute on rootfile
elements since the prose of EPUB 3.1 says the target of a rootfile
must be a Package Document, i.e. an OPF file... If EPUB 2 OCF could
directly target for instance a PDF file, it's not the case any more
for OCF 3.
- absolute URIs (for instance
/files/xhtml/index.html
with a leading slash, cf. path-absolute construct in
RFC 3986) are harmful to EPUB+Web convergence
- if multiple renditions are dropped, the
META-INF/container.xml
file becomes useless and it can be dropped.
- the prose for the
META-INF/manifest.xml makes me
wonder why this still exists: "does not mandate a format", "MUST NOT
be used". Don't even mention it! Just say that extra unspecified
files inside META-INF directory must be ignored (Cf.
OCF section 3.5.1) , and possibly reserve the metadata.xml
file name, period. Oh, and a ZIP is also a manifest of files...
- I am not an expert of encryption, signatures, XML-ENC Core or XML
DSIG Core, so I won't discuss
encryption.xml and signatures.xml
files
- the
rights.xml file still has no specified format.
Strange. Cf. item 8 above.
- Resource obfuscation is so weak and useless it's hilarious. Drop
it. It is also painful in EPUB+Web convergence.
- RNG schemas are not enough in the OCF spec. Section 3.5.2.1 about
container.xml file for instance shouls have models and
attribute lists for each element, similarly to the Packages spec.
- not sure I have ever seen
links and link
elements in a container.xml file... (Cf. issue
#374). The way these links are processed is unspecified
anyway. Why are these elements normatively specified since extra
elements are allowed - and explicitely ignored by spec - in the
container?
Packages
- a Package consists of one rendition only.
- I have never understood the need for a manifest of resources
inside the package, probably because my own publications don't use
Media Overlays or media fallbacks.
- fallbacks are an inner mechanism also similar to
multipart/alternative for renditions. I would drop it.
- I think the whole package should have properties identifying the
required technologies for the rendition of the Package (e.g.
script), and avoid these properties on a per-item basis that makes
no real sense. The feature is either present in the UA for all
content documents or for none.
- the
spine element represent the default reading
order of the package. Basically, it's a list. We have lists in html,
don't we? Why do we need a painful and complex proprietary xml
format here?
- the name of the
linear attribute, that discriminates
between primary and supplementary content, is extremely badly
chosen. I always forget what really is linear because
of that.
- Reading Systems are free, per spec, to completely ignore the
linear
attribute, making it pointless from an author's point of view.
- I have never seen the
collection element used and I
don't really understand why it contains link elements
and not itemref elements
- metadata fun, as always with every EPUB spec. Implementing
refines
in 3.0 was a bit of a hell (despite warnings to the EPUB WG...), and
it's gone from 3.1, replaced by new attributes. So no forwards
compatbility, no backwards compatibility. Yet another parser and
serializer for EPUB-compliant user agents.
- the old OPF
guide element is now a html landmarks
list, proving it's feasible to move OPF features to html
- the Navigation Document, an html document, is mandatory... So all
the logics mentioned above could be there.
- Fixed Layout delenda est. Let's use CSS Fragmentation to
make sure there's no orphaned content in the document
post-pagination, and if CSS Fragmentation is not enough, make
extension contributions to the CSS WG.
- without 3.0
refines, there is absolutely nothing any
more in 3.1 preventing Package's metadata to be expressed in html;
in 3.0, the refines attribute was a blocker, implying
an extension of the model of the meta html element or
another ugly IDREF mechanism in html.
- the
prefix attribute on the package element is a
good thing and should be preserved
- the
rendition-flow property is weird, its values
being paginated, scrolled-continuous, scrolled-doc
and auto. Where is paginated-doc, the
simplest paginated mode to implement?
- no more NCX, finally...
- the Navigation Document is already a html document with
nav
elements having a special epub:type/role
(see issue
#941), that's easy to make it contain an equivalent to the
spine or more.
Content Documents
- let's get rid of the epub namespace, please...
Media Overlays
- SMIL support across rendering engines is in very bad shape and the
SMIL polyfill does not totally help. Drop Media Overlays for the
time being and let's focus on visual content.
Alternate Style Tags
- terrible spec... Needed because of Reading Systems' limitations
but still absolutely terrible spec...
- If we get rid of backwards compatibility, we can drop it. Submit
extensions to Media Queries if needed.
On the fly conclusions
- backwards compatibility is an enormous burden on the EPUB
ecosystem
- build a new generation of EPUB that is not backwards-compatible
- the
mimetype file is useless
- file extension of the publication MUST be well-defined
- one rendition only per publication and no more
links/link
elements
- in that case, we don't need the
container.xml file
any more
metadata.xml and manifest.xml files
removed- we may still need
encryption.xml, signatures.xml
and rights.xml inside a META-INF directory (or
directly in the package's root after all) to please the industry.
application/oebps-package+xml mimetype is not
necessary- the EPUB spec evolution model is/was "we must deal with all cases
in the world, we move very fast and we fix the mistakes afterwards".
I respectfully suggest a drastic change for a next generation:
"let's start from a low-level common ground only and expand slowly
but cleanly"
- the OPF file is not needed any more. The root of the unique
rendition in a package should be the html Navigation Document.
- the metadata of the package should be inside the
body
element of the Navigation Document
- the spine of the package can be a new
nav element
inside the body of the Navigation Document
- intermediary summary: let's get rid of both
META-INF/container.xml
and the OPF file... Let's have the Navigation Document mandatorily
named index.xhtml so a directory browsing of the
uncompressed publication through http will render the Navigation
Document.
- let's drop the Alternate Style Tags spec for now. Submission of
new Media Queries to CSS WG if needed.
- let's drop Media Overlays spec for now.
CONCLUSION
EPUB is a monster, made to address very diverse markets and
ecosystems, too many markets and ecosystems. It's weak, complex, a bit
messy, disconnected from the reality of the Web it's supposed to be
built upon and some
claim (link in fr-FR) it's too close to real books to be
disruptive and innovative.
I am then suggesting to severe backwards compatibility ties and
restart almost from scratch, and entirely and purely from W3C
Standards. Here's the proposed result:
1. E0 Publication
A E0 Publication is a ZIP container. Files in the ZIP must be stored
as is (no compression) or use the Deflate algorithm. File and
directory names must be encoded in UTF-8 and follow some restrictions
(see EPUB 3.1 filename restrictions).
The file name of a E0 Publication MUST use the e0 file
extension.
A E0 Publication MUST contain a Navigation Document. It MAY contain
files encryption.xml, signatures.xml and rights.xml (see OCF 3.1 for
more information). All these files must be placed directly inside the
root of the E0 Publication.
A E0 Publication can also contain Content Documents and their
resources.
Inside a E0 Publication, all internal references (links, anchors,
references to replaced elements, etc) MUST be strictly relative. With
respect to section 4.2 of RFC 3986, only path-noscheme
and path-empty are allowed for IRIs' relative-part.
External references are not restricted.
2. E0 Navigation Document
A E0 Navigation Document is a html document. Its file name MUST be index.xhtml
if the document is a XML document and index.html if it
it is not a XML document. A E0 Publication cannot contain both index.html
and index.xhtml files.
A E0 Navigation Document contains at least one header
element (for metadata) and at least two nav html
elements (for spine and table of contents) in its body
element.
2.1. E0 Metadata in the Navigation Document
E0 metadata are designed to be editable in any Wysiwyg html editor,
and potentially rendered as regular html content by any Web browser.
E0 metadata are expressed inside a mandatory header
html element inside the Navigation Document. That element must carry
the "metadata" ID and the vocab attribute
with value "http://www.idpf.org/2007/opf". All metadata
inside that header element are then expressed using
html+RDFa Lite 1.1. E0 metadata reuse EPUB 3.1 metadata and
corresponding unicity rules, expressed in a different way.
Refinements of metadata are expressed through nesting of elements.
Example:
<header id="metadata"
vocab="http://www.idpf.org/2007/opf">
<h1>Reading Order</h1>
<ul>
<li>Author:
<span property="dc:creator">glazou
(<span property="file-as">Glazman, Daniel</span>)</span></li>
<li>Title:
<span property="dc:title">E0 Publications</span></li>
</ul>
</header>
The mandatory title element of the Navigation Document,
contained in its head element, should have the same text
contents than the first "dc:title" metadata inside that header element.
2.2. E0 Spine
The spine of a E0 Publication is expressed in its Navigation Document as
a new nav element holding the "spine" ID. The spine nav
element is mandatory.
See EPUB
3.1 Navigation Document.
2.3. E0 Table of Contents
The Table of Contents of a E0 Publication is expressed in its Navigation
Document as a nav element carrying the "toc" ID. The Table of Contents nav
element is mandatory.
See EPUB
3.1 Navigation Document.
2.4. E0 Landmarks
The Landmarks of a E0 Publication is expressed in its Navigation Document
as a nav element carrying the "landmarks" ID. The Landmarks nav
element is optional.
See EPUB
3.1 Navigation Document.
2.5. Other nav elements
The Navigation Document may include one or more nav
elements. These additional nav elements should have an role
attribute to provide a machine-readable semantic, and must have a
human-readable heading as their first child.
IDs "metadata", "spine" , 'landmarks" and "toc" are reserved in the
Navigation Document and must not be used by these extra nav
elements.
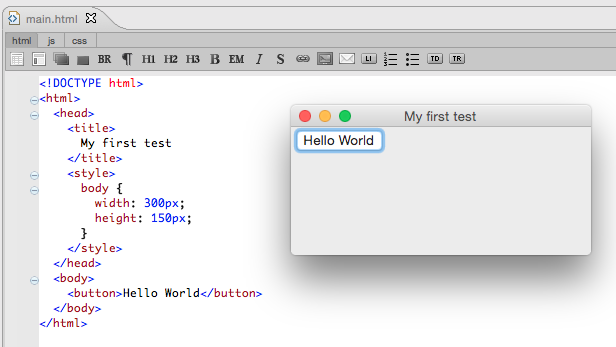
2.6. Example of a Navigation Document
<!DOCTYPE html>
<html lang="en">
<head>
<meta content="text/html; charset=UTF-8" http-equiv="content-type">
<title>Moby-Dick</title>
</head>
<body>
<header id="metadata"
vocab="http://www.idpf.org/2007/opf">
<ul>
<li>Author:
<span property="dc:creator">Herman Melville
(<span property="file-as">Melville Herman</span>)</span></li>
<li>Title:
<span property="dc:title">Moby-Dick</span></li>
<li>Identifier:
<span property="dc:identifier">glazou.e0.samples.moby-dick</span></li>
<li>Language:
<span property="dc:language">en-US</span></li>
<li>Last modification:
<span property="dcterms:modified">2017-01-17T11:16:41Z</span></li>
<li>Publisher:
<span property="dc:publisher">Harper & Brothers, Publishers</span></li>
<li>Contributor:
<span property="dc:contributor">Daniel Glazman</span></li>
</ul>
</header>
<nav id="spine">
<h1>Default reading order</h1>
<ul>
<li><a href="cover.html">Cover</a></li>
<li><a href="titlepage.html">Title</a></li>
<li><a href="toc-short.html">Brief Table of Contents</a></li>
...
</ul>
</nav>
<nav id="toc" role="doc-toc">
<h1>Table of Contents</h1>
<ol>
<li><a href="titlepage.html">Moby-Dick</a></li>
<li><a href="preface_001.html">Original Transcriber’s Notes:</a></li>
<li><a href="introduction_001.html">ETYMOLOGY.</a></li>
...
</ol>
</nav>
</body>
</html>
3. Directories
A E0 Publication may contain any number of directories and nested
directories.
4. E0 Content Documents
E0 Content Documents are referenced from the Navigation Document. E0
Content Documents are html documents.
E0 Content Documents should contain <link rel="prev"...> and <link rel="next"...> elements in their head element conformant to the reading order of the spine present in the Navigation Document. Content Documents not present in that spine don't need such elements.
The epub:type attribute is superseded by the role attribute and must not be used.
5. E0 Resources
E0 Publications can contain any number of extra resources (CSS stylesheets, images, videos, etc.) referenced from either the Navigation Document or Content Documents.